1. 변수
(1) 변수 생성
일반적으로 변수에 값을 넣어줄 때 <-를 사용한다.
# 변수에 값 저장
a <- 1
a+2
b <- a
(2) 벡터 생성
변수명 <- c(값, 값, 값)
변수명 <- c(2:5) : 2부터 5까지 [2,3,4,5]
seq(2,6) : 2부터 6까지 -2,3,4,5,6] (아무 parameter를 주지 않아서 그냥 하나씩 커지는 듯)
seq(1, 6, by=2) : 2씩 커짐, 따라서 출력값이 [1, 3, 5]
# 벡터 만들기
var1 = c(2, 3, 4, 5)
var2 = c(2:5)
var1
var2
var3 <- seq(2, 6)
var3
var4 <- seq(1, 6, by=2)
var4
(3) 문자변수
문자변수는 "" or ' '로
#문자 변수
str1 <- "aaa"
str1
2. Data Frame 만들기
(1) 벡터 변수들을 묶어서 만들기
data.frame(벡터변수, 벡터변수, 벡터변수 ...)
(2) 한 번에 벡터 변수(column)과 data frame 초기화도 가능
data.frame(벡터변수 <- c(값, 값, 값) , 벡터변수 <- c(값, 값, 값)
##### dataframe 만들기 ######
# 1. 각 column 별 row값 넣어주기
# 2. data.frame()으로 합침
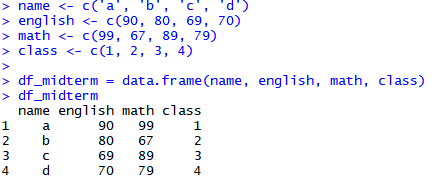
name <- c('a', 'b', 'c', 'd')
english <- c(90, 80, 69, 70)
math <- c(99, 67, 89, 79)
class <- c(1, 2, 3, 4)
df_midterm = data.frame(name, english, math, class)
df_midterm
3. 기본적 함수
mean(벡터), max(벡터), min(벡터)
예시) using mean()
# 각 column 별 평균 구하기
mean(df_midterm$english)
mean(df_midterm$math)
# NA = not a number
mean(df_midterm$name)
보면, 숫자가 아닌 name 칼럼의 평균을 구하려고 하면 warning이 뜨면서 '인자가 수치형 또는 논리형이 아니므로 NA를 반환합니다.'라고 한다. NA는 not a number이라는 뜻이다.
paste()
- 두 개를 (string)을 붙이는 함수
- collapse (parameter): 가운데 parameter에 해당하는 것을 넣어줌
#paste() 함수 - parameter 'collapse'
str2 <- c("hello", "world")
str2
paste(str2, collapse = ",")

4. 그래프용 ggplot2 패키지
(1) package install
install.packages("패키지명")
처음으로 패키지를 사용할 때만 설치해주면 된다. 이후 Rstudio에서 언제나 로드가능
(2) load package
libray(패키지명)
이렇게 하면 이 프로젝트에서 package 사용 가능!
#package install
install.packages("ggplot2")
#ggplot2 로드하기
library(ggplot2)
var1 <- c(2:7)
qplot(var1)
#mpg는 미국 자동차의 연비 데이터
qplot(data = mpg, x=cty)
install package 하면 콘솔에 엄청 많은 라인들이 뜨면서 다운로드 및 설치가 된다.
그러고 나서 library()를 통해 패키지를 불러오면 된다.
(3) 그래프 그리기
qplot(data=데이터프레임, x=column)은 그래프를 그리는 함수이다. (x 축으로 이루어진 그래프)

단순한 벡터라서 모두 1을 찍고 있다. (아무 의미 없다)

위에 있는 코드에서 불러면 mpg라는 데이터는 ggplot2 패키지에서 저장되어 있는 데이터 샘플이다. 그 파일의 데이터를 x=cty로 설정해서 그려준 것이다.
5. excel 파일에서 data 읽어오기
(1) excel을 읽기 위해 "readxl" 패키지를 다운 및 로드한다.
#install package and import
install.packages("readxl")
library(readxl)(2) df = read_excel("파일명")
df는 읽은 dataframe을 저장할 변수
* 참고로, 다른 주소없이 파일명으로만 해당 엑셀 파일을 읽기 위해서는 엑셀 파일이 현재 프로젝트 디렉터리에 존재해야 한다.
#read excel file and put it in dataframe
df_exam = read_excel("df_exam.xlsx")
df_exam
(3) df_exam$english
는 df_exam이라는 dataframe에서 english column을 뜻한다.
※ $를 사용한다!
mean(df_exam$english)
mean(df_exam$math)
(4) 엑셀 파일 내에 column명이 없으면 dataframe으로 읽어올 때 instance가 column명이 되므로, col_name 패러미터를 F(false)로 설정해준다.
#만약 엑셀 파일의 column 이름이 없다면 아래처럼 불러온다
#자동 할당된다 x_num 이런 식으로
df_exam2 = read_excel("df_exam2.xlsx", col_names = F)

(5) 엑셀 파일 내에 시트가 여러장일 경우 sheet 패러미터로 지정해준다.
#다른 시트에서 불러오기
df_exam3 = read_excel("df_exam2.xlsx", sheet = 2)
df_exam3
6. CSV 파일에서 읽기 / 쓰기
(1) 기본 함수로 읽어올 수 있음
read.csv("파일명")
### read from csv file ###
df_csv <- read.csv("csv_exam.csv")
df_csv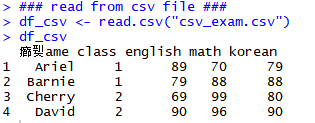
(2) 기본 함수로 출력할 수 있음 (csv 파일로)
write.csv(데이터프레임명, "파일명")
#### dataframe into csv file ###
df_w <- data.frame(english = c(90, 80, 60, 70),
math = c(50, 70, 100, 90),
class = c(1, 1, 2, 2))
df_w
write.csv(df_w, "df_w_exam.csv")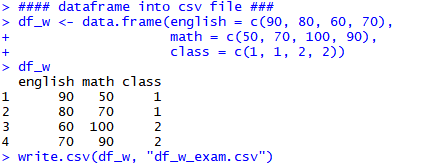
df_w_exam.csv 파일이 생긴 것을 확인할 수 있다.
7. 기본적 데이터 분석
(1) 기본적 함수 6개
- head() : head 파트를 프린트 (row1~6까지가 기본, 아래처럼 parameter로 원하는 수를 줄 수도ㅇ)
- tail() : head랑 비슷, 끝 row 6개 프린트
- View() : 대문자 주의! 다른 view창에 data frame을 표로 볼 수 있다
- dim() : dimension, 몇개의 column, row
- str() : data frame에 대한 특성 표현
- summary() : 데이터프레임에 대한 요약 내용 (평균, 최소, 최대 등등)
# data Analysis
#.1. Learn about data (basic functions)
df_exam
head(df_exam)
tail(df_exam)
View(df_exam)
dim(df_exam)
str(df_exam)
summary(df_exam)
head(df_exam, 3) #원하는 행 출력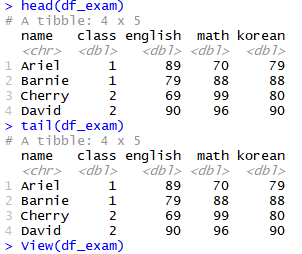



8. Rdata 파일
rda
- R 전용 파일
- 읽고 쓰는 속도가 빠름
- R을 사용하지 않는 경우에는 excel/csv를 사용
#### R data file ####
save(df_w, file = "df_w_exam.rda")
#dataframe 지우기
rm(df_w)
# load dataframe from rda file
load('df_w_exam.rda')(1) rda로 저장
save(데이터프레임, file = "파일명")
(2) 데이터프레임 지우기
rm(데이터프레임)
(3) rda에서 불러오기
load("파일명")
※ 변수에 저장 ㄴㄴ
9. mpg 데이터 사용(참고)
mpg는 ggplot 패키지에 있는 기본 데이터셋이다. 위에서 ggplot 패키지를 불러왔으니 변수에 저장해서 사용 가능하다.
아래의 코드처럼 mpg 데이터를 불러와서 위에 했던 것들을 실습해볼 수 있다.
(1) mpg 데이터 불러오기
as.data.frame(ggplot2::mpg)
- as는 변환 시 사용하는 명령어(~로 불러와라)
- ::는 패키지 안의 어떤 것을 뜻함

10. 변수 이름 바꾸기
(1) 변수 이름을 바꾸기 위해 dplyr 패키지를 다운받는다
(2) rename(데이터프레임, 바꿀column명 = 원래column명)
※ 여기서 굳이 copy를 만든건, 원래 data를 손상시키지 않기 위해 & 비교하기 위해
### 변수 이름(column) 바꾸기
install.packages("dplyr")
library(dplyr)
df_rename <- data.frame(var1 = c(1, 2, 1), var2 = c(2, 3, 4))
df_rename2 <- df_rename
df_rename
df_rename2 <- rename(df_rename2, v2 = var2)
df_rename2
#실습
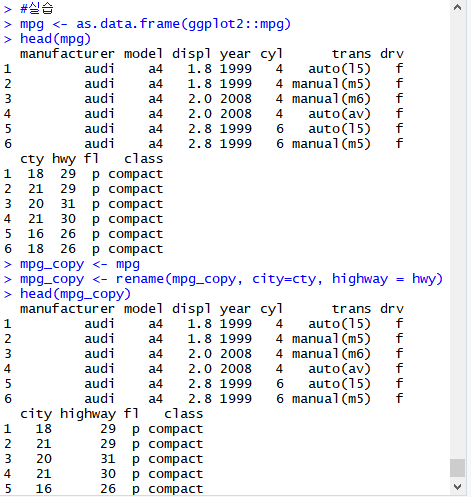
mpg <- as.data.frame(ggplot2::mpg)
head(mpg)
mpg_copy <- mpg
mpg_copy <- rename(mpg_copy, city=cty, highway = hwy)
head(mpg_copy)
11. 파생 변수 만들기
(1) 기본 (평균, 합 등을 하나의 column으로 만든다)
데이터프레임$새로운벡터변수 <- 기본변수연산
(2) ifelse를 사용하여 파생변수 만들기
데이터프레임$새로운파생변수명 <- ifelse(조건, 조건충족시값, 조건불만족시값)
*hist(column) 은 히스토그램을 그리는 함수
### 파생 변수 만들기 ####
df_var <- data.frame(var1 = c(4, 3, 8), var2 = c(2, 6, 1))
df_var
df_var$add <- (df_var$var1 + df_var$var2)
df_var
mpg_copy$total <- (mpg_copy$city + mpg_copy$highway)/2
head(mpg_copy)
min(mpg_copy$total)
summary(mpg_copy$total)
hist(mpg_copy$total)


'언어 > R' 카테고리의 다른 글
| [TS] foreign package is not available (0) | 2021.06.15 |
|---|---|
| 4. 그래프 그리기 (0) | 2021.06.15 |
| 3. 데이터 전처리 (0) | 2021.06.15 |
| 2. 미국 인구 데이터(midwest) 실습 (0) | 2021.06.15 |
| 0. R, R Studio설치 및 기본 (0) | 2021.06.15 |